
Llama 4 : un triplé gagnant pour Meta, qui bouscule l'IA mondiale

Meta vient de dévoiler une mise à jour majeure de sa famille de LLM Llama, un des modèles open source les plus utilisés en entreprise. Deux nouveaux modèles sont publiés sous licence open source avec des conditions d'usage spécifiques : Llama 4 Maverick et Llama 4 Scout. Pour cette mise à jour, Meta mise sur la multimodalité et l'efficience. La firme de Menlo Park remet également en cause la pertinence du RAG. Explications.
Une architecture efficiente
Avec Llama 4, Meta ne fait pas simplement évoluer Llama 3.3 mais change d'architecture. Jadis basé sur une architecture transformer classique, les modèles de Llama 4 tirent maintenant parti du MoE. Popularisé il y a un an déjà par Mistral AI avec Mixtral 8x22B et plus récemment avec DeepSeek R1, le MoE permet de gagner en efficience. Le modèle fonctionne sur la base d'experts. Chaque expert active seulement une partie des poids du modèle pour chaque token d'entrée. Cette approche permet donc de n'activer qu'une partie de l'ensemble des poids du modèle à l'inférence et donc de réduire considérablement les besoins énergétiques.
Llama 4 Scout compte 109 milliards de paramètres dont 17 milliards actifs à l'inférence et Llama 4 Maverick repose sur 400 milliards de paramètres dont 17 milliards à l'inférence également. Meta devrait publier par la suite Llama 4 Behemoth, un giga modèle à 2 000 milliards de paramètres dont 288 milliards actifs. C'est justement Behemoth qui a permis d'entraîner par distillation Maverick et Scout.
Les trois modèles partagent des modalités communes, chacun étant capable de traiter en entrée du texte, des images ou encore de la vidéo. Enfin, Scout et Maverick arrivent avec des fenêtres de contexte conséquentes de 10 et 1 millions de tokens. Un contexte qui ouvre la voie à de nouveaux usages, nous y reviendrons.

Des performances de pointe dans les benchmarks
Llama 4 Scout, malgré sa taille relativement modeste, surpasse tous les modèles Llama précédents et démontre des performances supérieures à Gemma 3, Gemini 2.0 Flash-Lite et Mistral 3.1 sur un large éventail de benchmarks. Particulièrement impressionnant en compréhension d'images et en raisonnement sur du contexte long, Scout établit un nouveau standard pour les modèles accessibles sur un seul GPU.
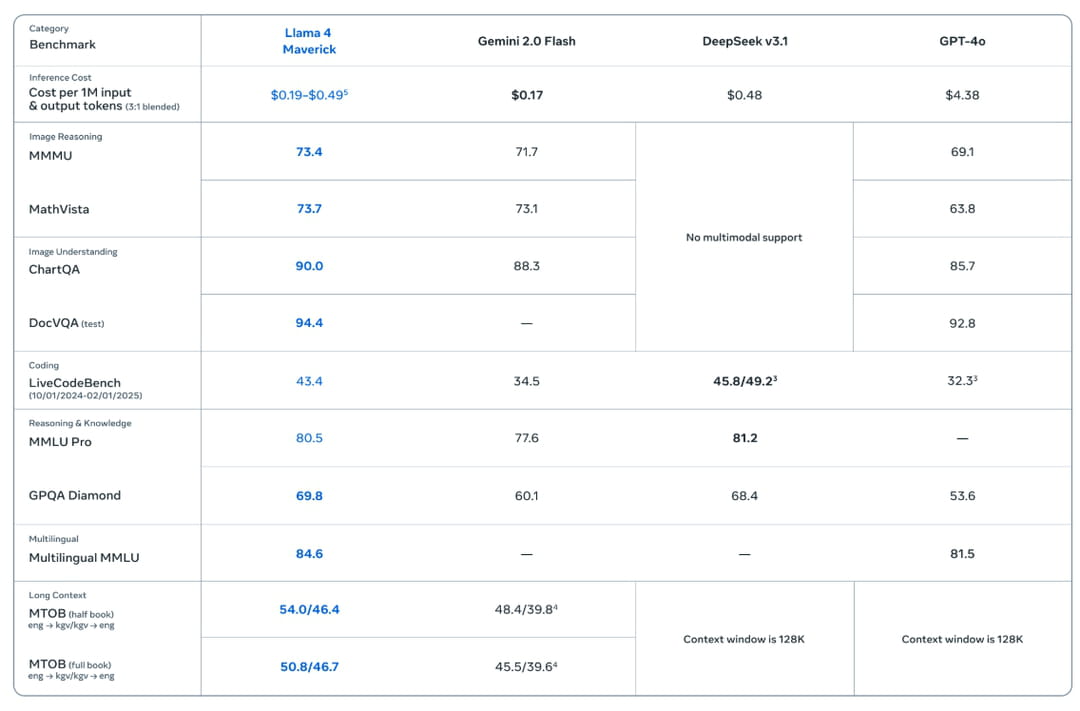
Llama 4 Maverick, lui, redéfinit les attentes pour les modèles multimodaux en battant GPT-4o et Gemini 2.0 Flash sur de nombreux benchmarks, tout en rivalisant avec DeepSeek v3 sur le raisonnement et le codage - et ce avec moins de la moitié des paramètres actifs. Sa version expérimentale finetunée pour le chat obtient un score ELO de 1417 sur LMArena confirmant ses bonnes capacités conversationnelles.
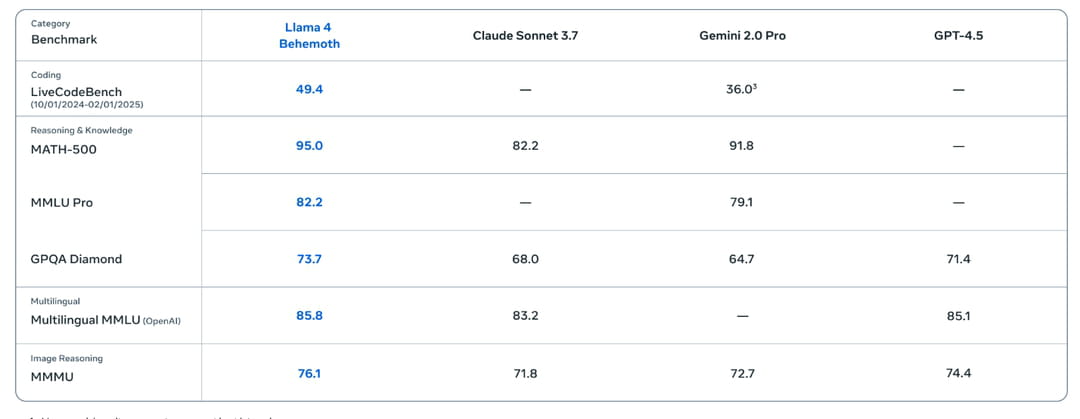
Le véritable tour de force vient cependant de Llama 4 Behemoth, qui bien que non disponible publiquement, démontre des capacités notables sur les benchmarks mathématiques. Le modèle surpasse GPT-4.5, Claude Sonnet 3.7 et même Gemini 2.0 Pro sur plusieurs tests scientifiques exigeants comme MATH-500 et GPQA Diamond. Meta ne compare toutefois pas son poulain au dernier modèle de Google DeepMind, Gemini 2.5 Pro.
La fin du RAG ?
Le véritable changement de Llama 4 vient sûrement de la taille de contexte offerte par les deux modèles déjà publiés (Maverick et Scout donc). Avec un contexte de 10 millions de tokens pour Scout et 1 million pour Maverick, la question de la pertinence du RAG revient sur la table. Est-il vraiment nécessaire d'utiliser un système de génération augmentée de récupération quand le modèle lui-même peut prendre en entrée autant de données ? La question se pose. Des tests devront être menés pour s'assurer que le modèle reste pertinent avec des tailles de contexte élevées dans un cadre opérationnel.
Si l'on considère qu'un mot en français représente environ 1.5 token, Maverick pourrait traiter des contextes d'environ 666 666 mots (environ 6 à 7 livres) et jusqu'à 6 666 666 mots pour Scout (soit environ 60 à 80 livres). De quoi envoyer des bases documentaires assez complètes. Enfin une telle taille de contexte permet également de traiter des vidéos assez longues, ouvrant là encore la voie à de nouveaux usages (analyse de vidéos de formation pour en extraire des points clés, analyse d'appels vidéo clients...).
Une licence (presque) open source
Avec le déploiement de Llama 4, Meta publie les modèles sous une nouvelle licence semi-ouverte. Les professionnels peuvent utiliser commercialement les modèles, les reproduire, les re-entrainer et même créer des modèles dérivés. Meta limite toutefois les droits d'utilisation et de re-exploitation aux entreprises disposant de moins de 700 millions d'utilisateurs actifs mensuels. Au-delà de ce seuil, il sera obligatoire de demander une licence spécifique directement à Meta. Le but est ici, très certainement, d'encadrer l'accès aux modèles pour éviter que des entreprises concurrentes dans l'IA ne se servent de Llama 4 pour entraîner leur propre modèle. Petit bonus : Meta explique également que quiconque la poursuivrait en justice pour des questions de propriété intellectuelle sur Llama verrait alors sa licence Llama 4 annulée.
Dans les prochains mois, il est fort à parier que bon nombre d'entreprises passent sur une des versions de Llama 4 pour diminuer les coûts à l'inférence ou développer de nouveaux cas d'usage multimodaux. La taille des modèles encore conséquente pourrait toutefois limiter, dans un premier temps, le déploiement sur site. Même en utilisant l'architecture MoE, l'ensemble des poids du modèle doit être chargé dans la mémoire du GPU. Llama 4 Behemoth et ses 2 000 milliards de paramètres devrait ainsi être distribué principalement à sa sortie chez les clouds providers.